Deep Dive
Building Local Semantic Search for All My Documents
The Trigger
Searching for a specific quote across PDFs, slide decks, and notes became frustrating when I couldn't recall exact keywords. Traditional filename search and Spotlight failed me. This pushed me to build a local semantic search system that understands meaning rather than relying on exact text matches.
What I Learned About Semantic Search
RAG (Retrieval-Augmented Generation) combines embeddings for capturing semantic meaning with intelligent retrieval to find relevant content chunks. Unlike keyword matching, embeddings enable queries like "async S3 uploads" to return relevant documents even when they use different terminology.
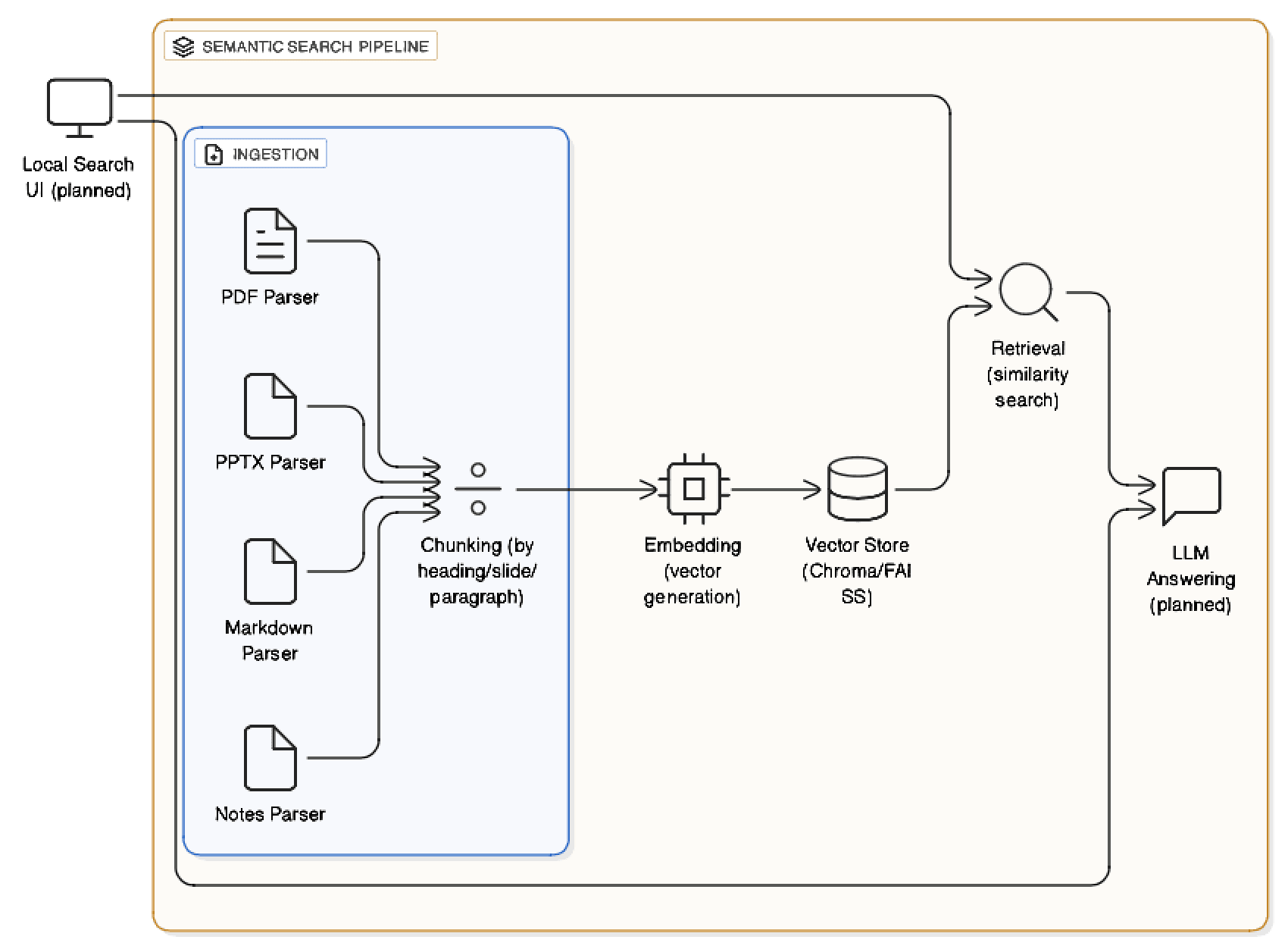
Architecture
- Ingestion: Parse PDFs, PPTX, text, and markdown files with intelligent chunking by headings and slides.
- Embedding: Generate vector embeddings using Sentence Transformers (all-MiniLM-L6-v2).
- Vector store: Index chunks in Chroma/FAISS with metadata (filename, page, slide number).
- Retrieval: Perform similarity search to return top-k relevant chunks.
- Answering: (Planned) Feed retrieved chunks to an LLM for summarization.
Here's the core implementation of the semantic search with hybrid scoring:
The TF-IDF Limitation
Initially, I used TF-IDF for ranking results. It worked for exact keyword matches but failed with multi-term queries, often returning documents with superficial keyword mentions over contextually relevant content. TF-IDF counts word frequencies without understanding semantic relationships. It can't connect related concepts or grasp broader context.
From Cloud to Local: The Embedding Journey
I started with OpenAI's text-embedding-3-small for quick validation. While it provided excellent semantic understanding, I hit context length limits when processing larger documents.
This led me to Sentence Transformers with the all-MiniLM-L6-v2 model. After resolving Python 3.13 compatibility issues, the local approach proved superior: unlimited context windows, no API costs, complete data privacy, and fast enough for real-time search.
Progress & Roadmap
- Completed: File parsers for PDF, PPTX, markdown; heading-aware and slide-level chunking; Sentence Transformers integration.
- In progress: Vector store optimization and batch embedding pipeline.
- Planned: Local web UI for search with snippet previews; optional LLM-based summarization over retrieved chunks.
Hybrid Search: Combining Semantic and Keyword Matching
Pure semantic search excels at understanding context but can struggle with short, specific keywords. When searching for terms like "API" or "Docker", embeddings might return contextually related but not directly relevant results.
The solution: Hybrid search that combines both approaches:
- Semantic score (0.0-1.0): Captures contextual meaning and relationships between concepts.
- Keyword boost (0.0-0.8): Rewards documents with exact keyword matches.
- Combined score: Merges both signals for optimal results: semantic understanding with keyword precision.
This hybrid approach delivers the best of both worlds: it understands semantic intent while ensuring documents with actual keyword matches rank higher when appropriate.
Implementation Notes
The system is designed to be local-first, keeping documents private while delivering intelligent semantic search. All processing happens on-device with no external API dependencies in the final implementation.
Key Learnings
- TF-IDF vs. Embeddings: Keyword-based ranking fails for semantic queries; embeddings capture context and term relationships.
- Hybrid search advantage: Combining semantic understanding with keyword matching solves the accuracy problem for short, specific queries.
- Cloud vs. Local trade-offs: Cloud APIs enable rapid prototyping but have context limits; local models offer unlimited context and privacy.
- Chunking strategy: Intelligent chunking by headings and slides significantly improves retrieval precision.
- Fail fast, iterate: Quick validation with cloud APIs proved the concept before investing in local infrastructure.
- Dependency management: Always verify library compatibility with your Python version before upgrading.
- Local vector stores (Chroma/FAISS) provide low latency and data privacy without sacrificing performance.